Machine Learning vs Traditional Software Development

As Machine Learning powered applications become more common, the need to understand the nuances and complexity of the workflow (estimating, developing, testing, deploying, and continuously improving) becomes more and more critical. Traditional software development, such as a web service or a mobile application is fairly well-understood — write some code (a program) to act on data and this produces an output. In this case, we understand how to plan, estimate, manage, develop, test, etc. With Machine Learning projects (at least with supervised learning), we provide the data and expected output and have the system generate the code/program (model). These are two inherently different approaches and so require different treatment.
The purpose of this discussion is to address some of these differences and how they can be handled.

In today’s Machine Learning applications, typically only a small fraction is comprised of actual Machine Learning code. This means that all of the typical traditional software development topics still come into play. That said, the portion of the system that is Machine Learning-related is quite significant. In addition to code, there is also now the Machine Learning model itself along with the data used to train the model. While there is certainly a lot of science in Data Science, there is also a lot of art.

Consider the following illustrative example. An organization has decided to develop an application to reduce email spam. This business problem must first be framed as a development / Machine Learning problem. In this case, we can re-frame “reduce spam” into determining if an email is spam or not spam and then blocking the spam.
In a traditional software development approach, various logic and business rules would be created to apply to each email to determine spam / not-spam. We could make a pretty good estimate at how long it would take to develop and implement the rules, if-then statements, etc.
With Machine Learning, WE are not building the rules but rather the data is, and so things become a little muddier. This spam / not-spam question is a binary classification problem and leads to several key points.
Since binary classification is a type of supervised learning, we will need labeled data — examples of emails that are spam as well as those that are not. Beyond just having lots of good, clean, labeled data, we will also need to take particular care not to introduce bias from our dataset. For example, if we trained our model on a set of emails that contained 90% legitimate and 10% spam, the model could just state that all emails are legitimate and be 90% accurate.
Binary classification is a relatively well-understood area and there are several applicable algorithms such as Factorization Machines, K-Nearest Neighbors (k-NN), Linear Learner, XGBoost, and others. The question then becomes, which do we choose? Clearly, knowing something about the various choices available to us will influence our decision (Factorization Machines was designed to capture interactions between features within high dimensional sparse datasets like click prediction and item recommendation — not our use case, so we can look elsewhere) but often only to narrow the list.
Let’s say we narrowed it down to trying Linear Learner and XGBoost. We’ll need to run experiments with each and determine the types of metrics we will use to determine which one yields better results. Once we have our results from our two different algorithms, we most likely still will not have a winner because there are a lot of additional considerations about our experiments that could impact the results such as: Would changing/wrangling/enhancing the data yield different results? What about hyperparameter optimization? Parameter values such as weights and biases are derived by the system during training, but hyperparameters (learning rate, random number seed, evaluation metric, number of rounds to run the training, etc.) are used to control the training process and must be set up front. Several experiments — along with a lot of trial and error — are required before we have a good feeling for which algorithm is actually best suited for our use case.
Once we have a model that best suits our needs and it has been put into production (obviously, we are skipping a lot of steps, but we are trying to keep things simple for illustration purposes), we will need to constantly monitor our model. As new and different data enters our system, do our results stay the same? Over time, likely not, and the model will need to be re-trained. Perhaps by this point, better algorithms or techniques will be available to us (if-then and for-loops stay the same but Machine Learning algorithms, frameworks, etc. are constantly evolving) and so we may need to practically start over.
As you can see, there is a lot of exploration, experimentation, and trial-and-error — and this example was a simple, well-defined space. Imagine the complexities involved when developing novel approaches or when working with poor-quality data. It may be much harder to effectively rephrase our business problem into a Machine Learning problem. We may have no idea of which algorithm(s) to use. We may need to spend an extraordinary amount of time getting our data into decent shape. Perhaps an ensemble of multiple different algorithms will work best. And on and on and on. We may spend weeks or months experimenting, trying to answer these questions, and have — to the outside observer — no tangible results to show for our work. This was only a simple example of how Machine Learning requires a different mindset compared with traditional software development.
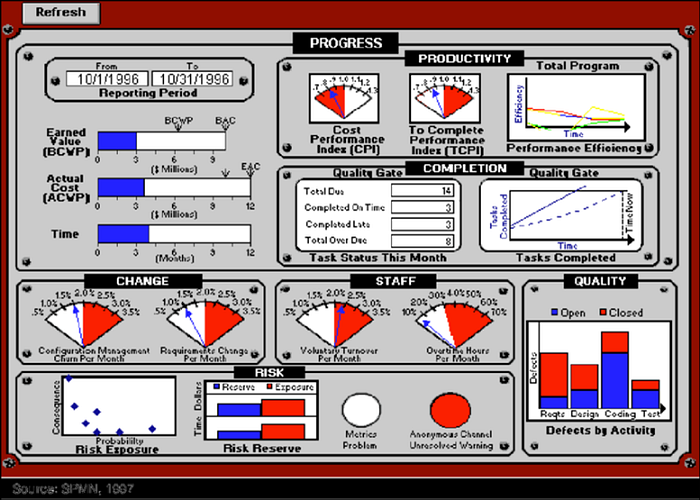
Program Management
Program management requires a solid understanding of managing resources. Be it time (scheduling), money (budget), people (human capital), etc. — reasonably accurate level-of-effort estimates are pretty important. Over the years (the above graphic is 25 years old!), managers have become relatively adept at providing these estimates for traditional software development projects. Depending on the methodology used (waterfall, agile, etc.), the phase names may change a bit, but in general, we need to estimate the following:
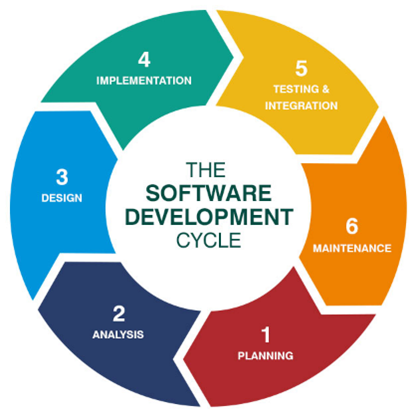
1. Planning, req gathering
2. Analysis & Design
3. Development / implementation
4. Testing (unit, regression, integration, etc.)
5. Deployment
6. Maintenance, evaluation, review
These are all straightforward (relatively speaking) to estimate resources for.
Now consider Machine Learning…
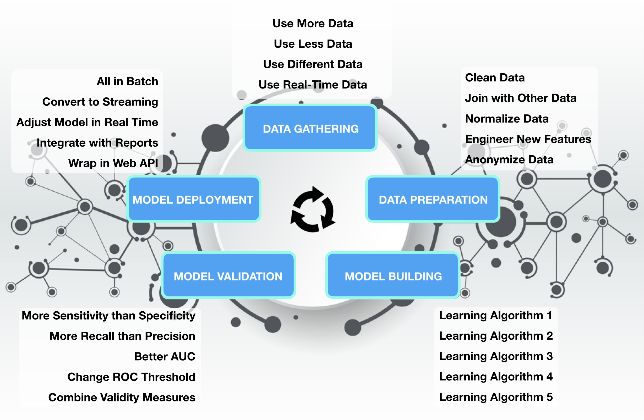
1. Determine and gather the right data to use.
Do we have enough? Too much? Would different data be better? Does it match real-world expectations?
2. Prepare the data.
Pre-process, analyze, clean, transform, normalize, drop, feature engineer, anonymize, etc.
3. Build / train / debug / optimize the model.
Compare several algorithms. Could things be improved with modified data? Optimize the hyperparameters. Utilize different metrics.
4. Evaluate the model.
This includes things like comparing performance of an established metric on a validation dataset, visualizing plots such as precision-recall curves, analyzing operational statistics such as inference speed, scrutinizing examples where the model was most confidently incorrect.
5. Deploy the model.
Will we be making batch or real-time inferences? Will the model be deployed separately (such as an API-call, in which case we’ll need an architecture to support it), embedded in the application, other?
6. Monitor the model.
Watch for model drift. New data needs to be fed back into the model regularly to (hopefully) improve it.
As you can see, there is experimentation nearly every step of the way. This means that estimating resources becomes far more challenging because it’s hard to tell in advance how easy or hard something is. Which is harder — beating a Grand Master in chess or driving a car? For people, it’s the former, for Machine Learning, it’s the latter.
Traditional software development projects generally move forward showing progress, but Machine Learning projects can completely stall for a week (or more) spent on modeling data to result in no improvement (observable progress) whatsoever. Remember, Machine Learning is still somewhere between “research” and “engineering”.
Beyond the uncertainties of experimentation, there is also the question of “Does real-world production data look a lot like the training data?”. Sometimes, the answer is no — which means the model seemed to do well during testing but then failed miserably in production, resulting in a lot of re-work.
Best Practices for Managing Machine Learning Projects
How can we hope to manage so much experimentation and uncertainty? With patience and understanding.
- Be sure to fully understand the problem to be solved and whether or not Machine Learning is really needed. Often people look for a problem where they can use Machine Learning when the better approach is to consider Machine Learning as one of many tools in your toolbelt and only use it when necessary. In other words, when approaching a problem, try to keep it simple!
- Consider using Probabilistic vs. Deterministic project scheduling. Deterministic scheduling is the most commonly used scheduling technique. In this method, the schedule developed is a network of activities linked by dependencies. Probabilistic scheduling is often better when uncertainty is greater. Statistical tools like PERT, Monte Carlo Simulations, etc. are used to estimate project duration, task dates, project dates, and develop the Gantt chart. If you are unfamiliar with this technique, here is a short paper on Probabilistic and Deterministic project scheduling techniques.
- Schedule time for thorough data exploration up front. Once the data is more fully understood, better resource estimation is far more likely.
- Get something working end-to-end right away to demonstrate quick wins. Create the simplest thing that might work and get it into the hands of users for feedback. As part of this effort, develop end-to-end data pipelines and Machine Learning pipelines. Identify lessons learned and areas for improvement then improve one thing at a time.
- Have data scientists and engineers work together. There are typically numerous roles involved in Machine Learning projects (DevOps engineer, data engineer, ML engineer, etc.) and all have different skillsets. Often, the term Data Scientist is used as a blanket term for all of the aforementioned skillsets. Set your team up for success by ensuring you have folks to create/maintain the infrastructure, wrangle the data, train/deploy the models, etc.
- Try using a variety of approaches. Use a combination of Probabilistic and Deterministic project scheduling. Allow time for exploration and experimentation but use standard scheduling for other parts of the process. Measure progress based on inputs, not results. Modify sprint lengths when appropriate.
- Educate leadership on Machine Learning timeline uncertainty. Share some of the ideas in this post with management, stakeholders, etc. to help them better understand the process. When there is no “tangible progress”, share infographics on the experimentation that has occurred, lessons learned, etc.
Testing
As previously discussed, there are a lot of moving parts in the Machine Learning process. Things like:
- Collect and prepare training data
- Set up and manage environments for development
- Determine which algorithm(s) to use (experimentation)
- Set up and manage environments for training
- Train, debug, and tune models (experimentation)
- Deploy model in production
- Monitor models
- Validate predictions
- Scale and manage the production environment
As these topics are for the data scientists to handle, further details are beyond the scope of this discussion.
The two areas of the Machine Learning process we find typically result in the most friction with leadership due to a lack of understanding are program management and testing. In the preceding section we addressed the former, now it is time to discuss the latter.
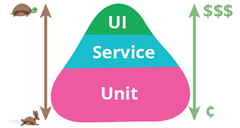
The test pyramid is a way of thinking about how different kinds of tests should be used for an application. Its key point is that you should have many more low-level unit tests than say regression, integration, or user interface tests.
Machine Learning system testing introduces more complexity than manually coded systems. Remember, we need to perform both model evaluation (metrics summarize performance on a test dataset) as well as model testing (explicit checks for expected behavior). Here are just some of the additional types of testing needed:
- Validating data — Input data vs. the expected schema, validating our assumptions about its valid values, are engineered features calculated correctly, etc.
- Validating model quality — Collect and monitor various metrics to evaluate a model’s performance, such as error rates, accuracy, area under the curve (AUC), receiver operating characteristic (ROC), confusion matrix, precision, recall, etc. These are also useful during hyperparameter optimization.
- Validating model consistency — Does the model perform as expected on real-world data? Does increasing the number of bathrooms (holding all other features constant) result in an increase in predicted home price (at least not a decrease)? Does changing a name from male to female (say Bob to Susan) or to a clearly international name (Smith to Shivamoggi) impact the results?

With more types of testing, we need to rethink the shape of our Test Pyramid. Unit, regression, integration, and user interface tests are still necessary, but clearly not sufficient. To the left is an example of how one might combine different test pyramids for each type of artifact (data, model, and code), as well as how to combine them.
If you have made it this far — Congratulations! You now have (hopefully) a better idea of some of the ways that Machine Learning projects are inherently dissimilar to traditional software development, and so require different treatment. Disparities in activities such as estimating level-of-effort and testing need to be effectively communicated to leadership so that realistic expectations can be set.
We hope you have found this information helpful and welcome any feedback. After all, this entire document was authored by an AI. Ok, that’s not exactly true, but the interesting thing in today’s world is that it could have been…
Credits
Editorial review by Jennetta George, Matt Cintron, and Joe Webb, PhD.
https://www.slideshare.net/sergeykarayev/machine-learning-teams-full-stack-deep-learning
https://medium.com/@l2k/why-are-machine-learning-projects-so-hard-to-manage-8e9b9cf49641
https://www.jeremyjordan.me/testing-ml/
https://scikit-learn.org/stable/tutorial/machine_learning_map/
https://martinfowler.com/bliki/TestPyramid.html
https://martinfowler.com/articles/cd4ml.html
https://www.theguardian.com/commentisfree/2020/sep/08/robot-wrote-this-article-gpt-3
